










Par Olenka Van Schendel
Sur les systèmes modernes et distribués, les tests unitaires sont sans doute l’élément le plus efficace de votre stratégie de test. Une batterie de tests unitaires bien conçus « impose » la qualité de votre application au fur et à mesure de son développement – et idéalement même avant. Les éléments des tests unitaires sont ensuite réutilisés en continu pendant toute la durée de vie de l’application afin de détecter toute régression dans le système.
Mais comment les tests unitaires peuvent-ils profiter aux applications existantes sur IBM i – et en particulier à celles qui n’ont pas été conçues dans une optique « unitaire », et où le code monolithique a toujours été la norme ?
Dans cet article, nous examinerons l’importance des tests unitaires en général et évaluerons la pertinence de cette technique sur IBM i.
Sommaire
- La qualité à partir de la quantité
- Classification des défauts
- « Shift Left » – détecter les erreurs le plus tôt possible
- Un code « atomique » propre
- Qu’en est-il de l’IBM i ?
- L’importance de l’automatisation des tests sur IBM i
- Garantir l’adoption des tests unitaires par les développeurs
- La différence avec Arcad i Unit
- Conclusion
1. La qualité à partir de la quantité
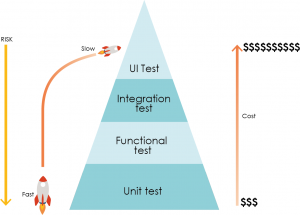
Les tests unitaires sont souvent négligés au profit de techniques plus orientées « business » comme les tests fonctionnels ou de bout en bout. Les tests unitaires prennent un temps précieux aux développeurs, surtout sur une base de code ancien comme IBM i qui n’est pas particulièrement structuré en « unités ». Alors comment un test unitaire par « boîte blanche », sans connaissance des fonctionnalités réelles de l’application, peut-il sauvegarder la qualité et la précision de votre système, sans parler de la réduction de vos coûts de développement ?
La solution réside dans la quantité et la couverture des tests.
Les tests unitaires impliquent la création d’une multitude de petits cas de tests très simples. Chaque test isole une section particulière du code (comme une procédure, un sous-programme, un bloc conditionnel), définissant le succès ou l’échec en termes de valeurs attendues des paramètres de sortie pour une entrée donnée. L’exécution du test est ensuite stockée comme « ligne de base », et les tests ultérieurs sont évalués par rapport à ce résultat. Cela rend les tests unitaires très efficaces pour détecter les régressions dans le système. Ils peuvent être réutilisés, regroupés et exécutés dans le cadre d’une suite à tout moment, par exemple après chaque build du système, après un changement d’environnement, ou avant qu’un composant particulier ne soit transféré aux testeurs QA. Les tests unitaires créés au début de la phase de développement peuvent être utilisés plus tard comme « smoke test » d’une application, afin de détecter les erreurs basiques et éviter de perdre du temps avec des tests plus sophistiqués.
2. Classification des défauts
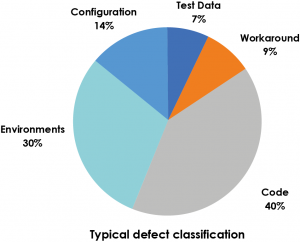
En effet, les classifications de défauts typiques révèlent que les défauts des logiciels peuvent être attribués à une grande variété de causes, notamment :
- Erreurs dans la spécification, la conception et la mise en œuvre du logiciel et du système
- Erreurs dans l’utilisation du système
-
Anomalies dans l’environnement
- Dommages intentionnels
- Conséquences potentielles des erreurs antérieures
Des enquêtes récentes ont montré que jusqu’à 55 % des défauts sont dus à des erreurs présentes dans le cahier des charges.
Il a également été observé qu’environ 40 % du temps d’un testeur est consacré aux anomalies d’environnement, ce qui a un impact important sur la qualité et la productivité.
Les nombreuses causes « périphériques » des défauts signifient que les coûts globaux des tests peuvent être considérablement réduits en réutilisant les cas de tests unitaires dans les « smoke tests », avant d’entreprendre des tests de systèmes coûteux à grande échelle.
3. « Shift Left » – détecter les erreurs le plus tôt possible
Les tests unitaires ne sont qu’une des nombreuses techniques des développeurs qui permettent de détecter les défauts le plus tôt possible dans le cycle de développement. Outre l’analyse statique du code, l’examen du code par les pairs, l’analyse de la couverture du code et d’autres pratiques, les tests unitaires permettent de détecter les erreurs le plus tôt possible, au moment où elles sont le moins coûteuses.
L’investissement en temps du développeur pour créer le test dans un premier temps peut être compensé par l’automatisation du processus de création. L’essentiel est de se concentrer sur des cas d’utilisation typiques qui affectent le comportement du système. La combinaison de « happy path » et de « edge cases » rend les tests unitaires encore plus efficaces.
Utilisés en continu dans un cycle CI/CD, les tests unitaires permettent de déterminer précisément dans quelles lignes de code se trouve le défaut. Les bugs sont corrigés avant même qu’ils ne quittent les mains du développeur !
4. Un code ‘atomique’ propre
Plus de 90 % des coûts de développement de logiciels sont consacrés à la maintenance des systèmes existants. La création de tests unitaires au fur et à mesure que vous développez du code améliore la conception du code et le rend plus facile à comprendre par les équipes de développement futures. En plus d’être plus fiable, le code testé à l’unité est plus simple, plus modulaire et donc plus facilement réutilisable. Cela permet de réduire la dette technique et de diminuer les coûts de développement à long terme.
Dans sa forme extrême, le « Test Driven Development » apporte une clarté supplémentaire même lors de la définition des prérequis en créant des tests avant le code lui-même.
5. Qu’en est-il de l’IBM i ?
Les applications IBM i modernes conçues avec une architecture ILE séparent déjà les règles de gestion, la persistance des données et l’interface utilisateur en modules ou fonctions distincts, ce qui facilite grandement l’automatisation des tests unitaires. Les points d’entrée et de sortie d’un module sont clairs, de sorte qu’il est relativement facile de définir un état « réussite/échec ».
Cependant, de nombreuses applications sur IBM i contiennent encore des sections de code source qui ont été développées il y a 40 ans et qui sont « trop importantes pour être touchées ». Cela crée une situation très précaire dans laquelle le risque et le coût de la refonte du code monolithique ou spaghetti en unités ou modules sont très élevés. Oui, le prix à payer pour ne rien faire doit être dépassé par une approche plus agile. Heureusement, les tests unitaires créent le filet de sécurité dont vous avez besoin lorsque vous modularisez votre code existant. En générant et en relançant des tests unitaires sur des applications » back-end » au fur et à mesure que vous les modifiez, vous vous assurez que les déploiements précédents fonctionnent toujours lorsqu’ils sont combinés à de nouvelles fonctionnalités.
Ce type de technique de « Test Driven Maintenance » (TDM) permet d’effectuer des tests unitaires à la demande et par lots, comme une sorte de système d’alerte précoce pour empêcher l’apparition de régressions lorsque vous « démêlez » votre ancien code.
Pour être pleinement adoptée par les développeurs, toute fonctionnalité de test unitaire sur IBM i doit être intégrée dans l’environnement de développement RDi, et aussi avec des outils standards tels que Jenkins et JUnit pour encourager le partage des outils entre les équipes multi-technologiques. Les meilleures solutions de tests unitaires sur IBM i peuvent automatiser à la fois la création et l’exécution des cas de test, en utilisant la technologie d’analyse syntaxique pour rechercher les paramètres et leurs types de données et identifier rapidement toutes les entrées et sorties du programme testé. La connaissance des références croisées et des dépendances permet également de gérer les cas de test et de réutiliser les cas entre les versions.
6. L’importance de l’automatisation des tests sur IBM i
Il existe encore quelques cas extrêmes où les applications IBM i ne peuvent pas être facilement remaniées et où le coût/temps de restructuration du code est prohibitif.
Dans ce cas, l’automatisation des tests fonctionnels est la meilleure option. Les cas de test sont créés automatiquement lorsque les utilisateurs exécutent les fonctions de l’application à partir de l’interface utilisateur standard. Contrairement aux tests unitaires où l’environnement de données sous-jacent est dynamique, les données de test fonctionnel sont statiques et restaurées avant chaque exécution de test afin de détecter les régressions par simple comparaison des données, sortie spool et interface utilisateur. Il n’y a pas de notion de succès ou d’échec, seulement des différences.
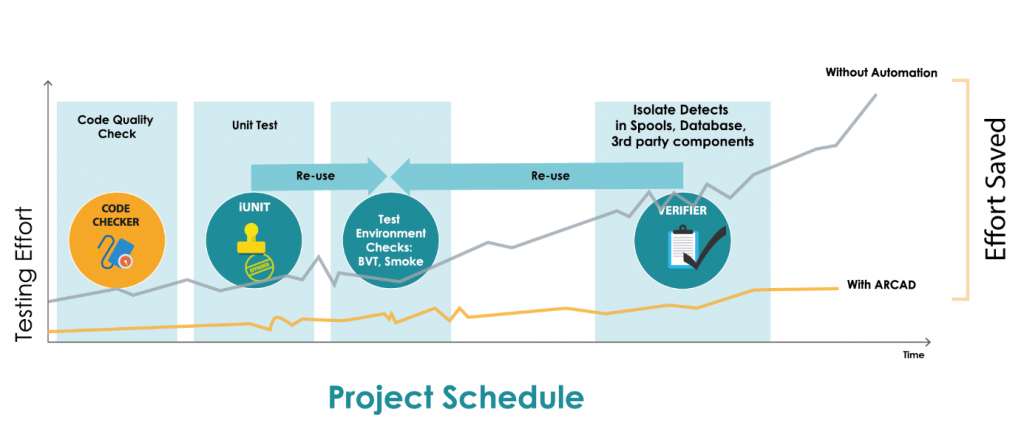
Bien sûr, une stratégie de test optimale combine à la fois une automatisation des tests unitaires et des tests fonctionnels pour minimiser le temps moyen de réparation (MTTR) des défauts dans leur ensemble. La réutilisation et le partage des cas de test évitent une perte de temps coûteuse pour le développeur et font des tests une activité continue, partie intégrante du cycle global CI/CD.
7. Garantir l’adoption des tests unitaires par les développeurs
En conclusion, nous avons vu que les tests unitaires facilitent un style de test « bottom-up », en validant les parties individuelles d’un programme avant de tester la « somme de ses parties » – une approche qui anticipe les défauts restants et réduit l’effort des tests d’intégration ultérieurs.
Les tests unitaires agissent comme une sorte de « documentation vivante » du système, permettant une compréhension rapide de l’interface d’une unité. Dans le cas d’un « Test Driven Development », ils peuvent même remplacer une spécification détaillée.
Cependant, les tests unitaires doivent être effectués en parallèle avec d’autres formes de tests, car ils ne permettent pas de détecter les erreurs au niveau du système ou les erreurs fonctionnelles, ni les aspects non fonctionnels tels que les performances.
Le principal défi des tests unitaires est la création de tests réalistes et utiles, afin d’établir les conditions initiales pertinentes qui reflètent l’exécution normale d’une application. Plus important encore, les tests unitaires doivent être maintenus en parallèle avec le processus de changement d’application lui-même, afin de garantir que les tests impactés soient maintenus à jour et exécutés pour chaque changement de code dépendant. Pour faciliter la maintenance des tests unitaires, il doit être facile de ré-identifier les nouveaux champs d’entrée et de sortie à mesure que l’application évolue. Sinon, les tests unitaires peuvent devenir aussi bogués que le code qu’ils sont censés tester !
Pour surmonter ces difficultés, les tests unitaires doivent être hautement automatisés et faire partie intégrante du cycle de livraison continu :
- Détection automatique des entrées et des sorties pour automatiser la création de tests réalistes/utiles
- Intégration des tests unitaires dans le processus de contrôle de version
- Auto-exécutions des tests en tant que partie continue du flux CI/CD
- Réutilisation des actifs des tests unitaires pour chaque changement de programme
- Maintenance/mise à jour des tests unitaires en fonction des dépendances
En résumé, les essais unitaires sont très bénéfiques mais imposent une certaine rigueur, nécessitant une automatisation maximale pour une adoption à long terme !
8. La différence avec Arcad i unit
ARCAD iUnit a été conçu pour maximiser l’automatisation tout au long du processus de test unitaire sur IBM i. En tant que tel, il peut même être utilisé par des développeurs qui ont peu ou pas de connaissances de l’application à tester.
Tout ce dont ARCAD iUnit a besoin pour commencer à travailler est un nom de bibliothèque. Il en découle un référentiel de connaissances sur les objets contenus dans la bibliothèque, utilisé pour aider le développeur à chaque étape du processus.
Une fois qu’ARCAD iUnit a analysé le contenu de la bibliothèque, l’outil guide le développeur dans la création et l’exécution des tests à partir d’une interface graphique facile à utiliser. Toutes les tâches les plus fastidieuses sont entièrement automatisées, telles que :
- l’identification de toutes les procédures d’un programme et de leurs paramètres d’entrée/sortie
- la définition des résultats attendus
- obtention/réglage de valeurs
- marquage/suivi des variables
- exécution des tests – individuellement ou en tant que suite
- exportation de tests vers JUnit
- ‘mocking’ de base de données, pour injecter des données dans une table avant l’exécution du test
- ‘mocking’ d’un programme, pour changer le comportement par défaut du programme
- exécution de projet « libre », pour gérer les programmes manquants
- intégration avec plusieurs outils d’automatisation : Jenkins, Azure Pipelines, CloudBees, GitLab CI…
L’introduction de ce niveau d’automatisation fait avancer le développement d’applications IBM i dans le monde DevOps « continu » qui est caractéristique sur les systèmes distribués – avec tous les avantages que cela apporte en termes de fiabilité de l’application, de retour sur investissement, d’élimination de la dette technique ou encore de continuité de l’activité pour en nommer quelques-uns.
9. Conclusion
En bref, les tests unitaires sont un maillon indispensable et souvent manquant du développement logiciel sur IBM i.
Les tests unitaires automatisés peuvent rendre un pipeline DevSecOps sur IBM i véritablement continu – avec des avantages mesurables en termes de qualité, de vitesse et de coût.
Pourtant, l’adoption des tests unitaires et le taux de retour dépendent du degré d’automatisation offert par l’outil de test unitaire. Pour obtenir un portail de qualité sécurisé, seuls les outils capables de décharger TOUTES les tâches de création de tests de routine du développeur avec suffisamment de flexibilité pour s’adapter à un environnement changeant, seront adoptés à long terme. En ce qui concerne l’IBM i, ARCAD iUnit apporte un niveau d’automatisation sans précédent et un ROI prouvé, quelle que soit la variante de langage utilisée.

Olenka Van Schendel
VP Strategic Marketing & Business Development
Avec 28 ans d’expérience dans les systèmes distribués et IBM i, Olenka a débuté dans le domaine de l’intelligence artificielle et du traitement du langage naturel, en travaillant comme ingénieur logiciel, principalement sous UNIX. Elle s’est rapidement spécialisée dans le développement d’outils logiciels intégrés comprenant des compilers, des débuggers et des systèmes de gestion du code source. En tant que VP Business Development au sein du groupe ARCAD Software, elle continue à se consacrer à la gestion du cycle de vie des applications (ALM) et à l’outillage DevOps dans une perspective multiplateforme, notamment IBM i.

DEMANDEZ VOTRE DÉMO
Parlons de votre projet !
Nos experts vous conseillent